Batch & Stream inferencing
What's a batch microbatch & stream inferencing and how to implement it

Overview
Microbatch inference is a machine learning technique that processes data in smaller, more frequent batches compared to traditional batch processing methods, enabling faster and more responsive model updates.
this technique has the advantage of processing smaller subsets of data at a time, which can improve computational efficiency and resource utilization compared to traditional batch processing.
Input data handling
Data Processing approaches : Batch , micro-batch and streaming
There are various data processing techniques, such as batch, stream processing, and micro-batch, that can be used for processing any volume of data.
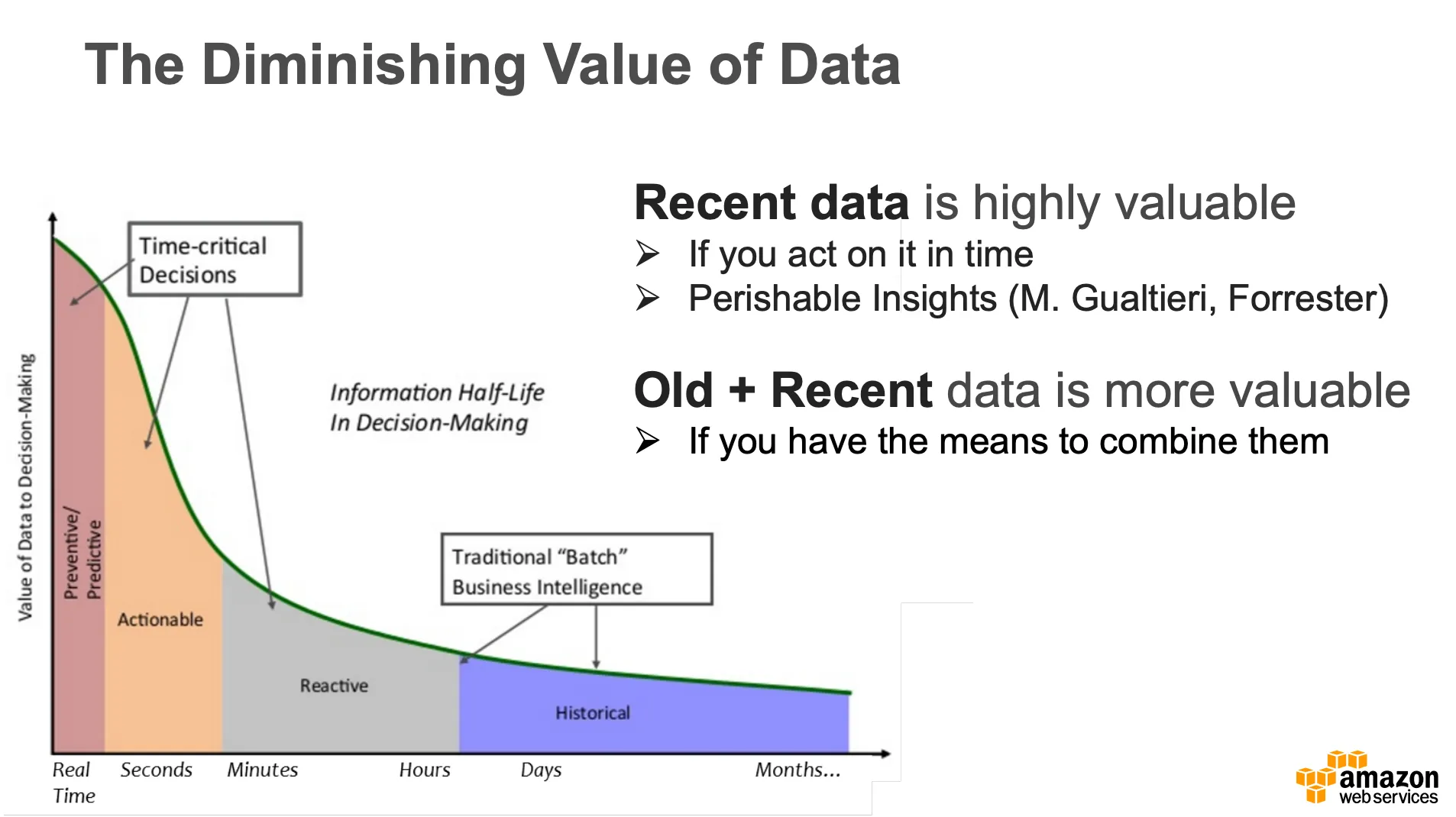
The diminishing value of data refers how much value is being created based on your processing approach.. It is a very beneficial strategy to analyze the most recent facts and make a decision based on the results. Time-sensitive judgments must be made in a matter of minutes. Assume for the moment that you are searching for running shoes to replace your current pair. You can view the running shoe advertisement you’re looking for by jumping to any website that has an advertisement window.
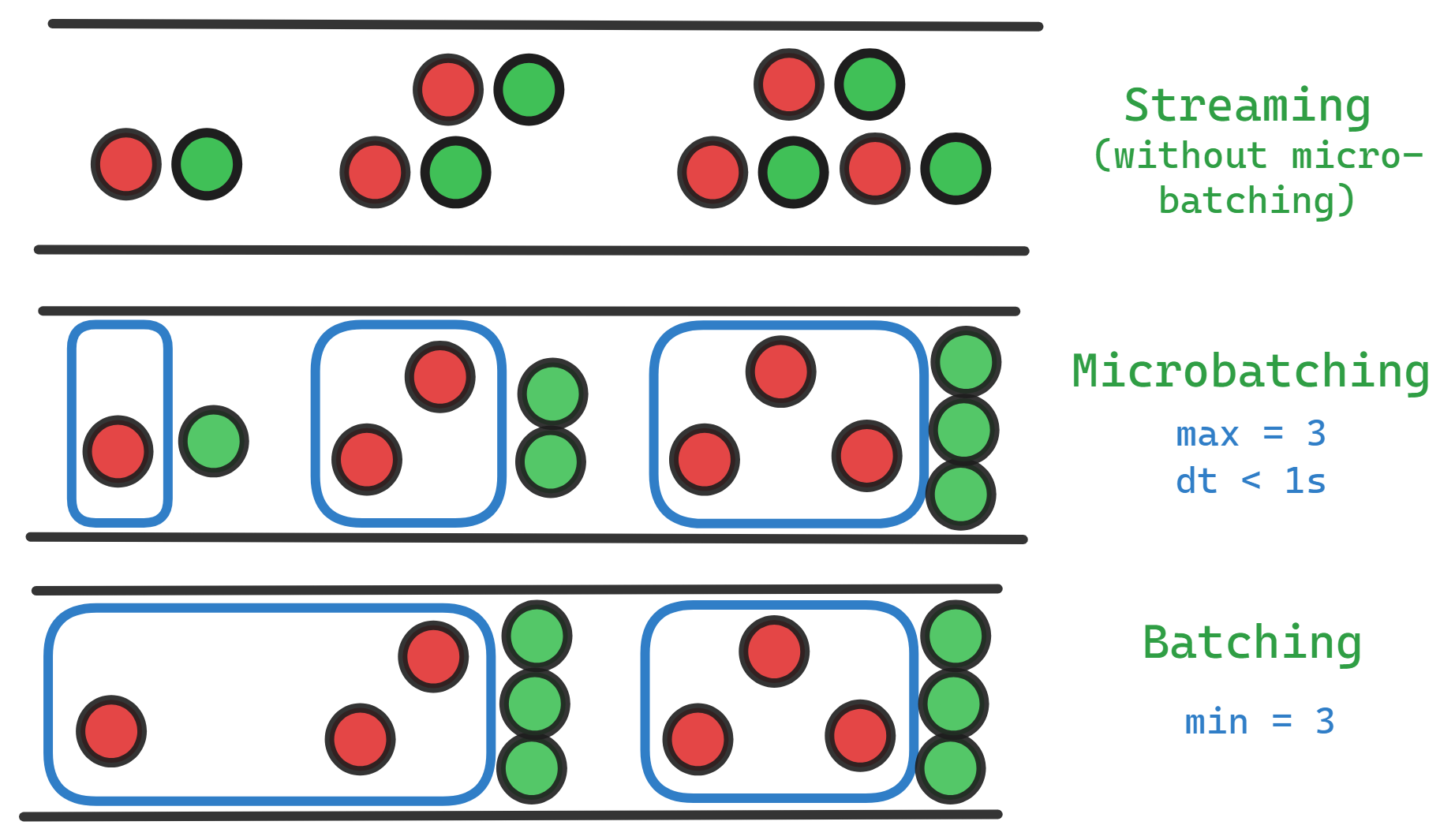 Figure 1.0: Diminishing value of data over time
Figure 1.0: Diminishing value of data over time
Batch Processing
Batch processing collects and processes data in large sets at scheduled intervals. Data is first stored in systems like SQL databases or data lakes and then processed using engines like MapReduce or Spark. It is ideal for use cases where real-time processing isn’t necessary, such as financial reporting or payroll.
Stream Processing
Stream processing handles data as it arrives, enabling real-time processing without waiting for all data to be collected. It is useful in scenarios like monitoring IoT sensors, detecting fraud in banking, or tracking real-time user activity.
Microbatch Processing
Microbatch processing combines batch and stream approaches by processing small chunks of data at frequent intervals. This method is suited for applications that require near real-time insights but without the complexity of full stream processing, such as in Spark Streaming.
Batching strategies
Simultaneous Batching :
Tasks are grouped into batches, and all batches are processed at the same time. Each batch can have a maximum size, and if there are fewer tasks than the limit, the batch will contain fewer items.
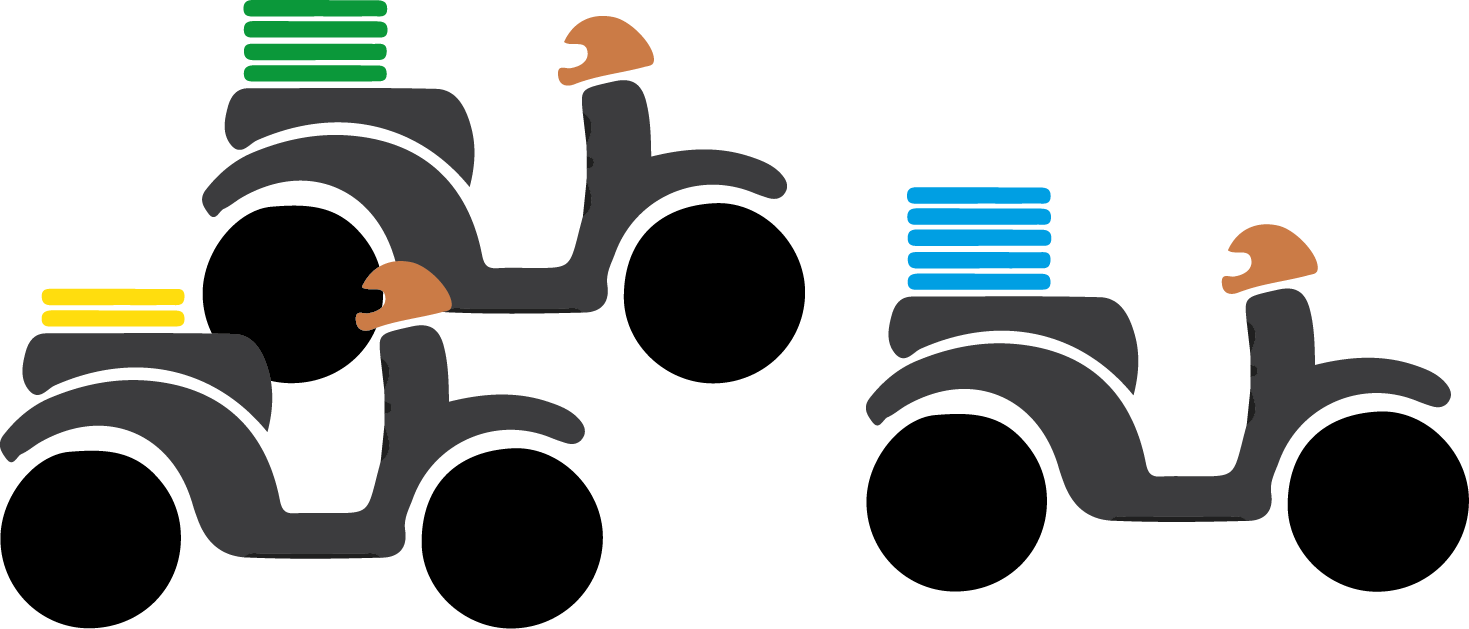 Figure 2.0: Simultaneous batching strategy
Figure 2.0: Simultaneous batching strategy
Example: In a food delivery service, four orders are grouped into a batch, and all four are delivered at the same time by different drivers. If only three orders are ready, the fourth slot remains empty, but the batch still proceeds.
Sequential Batching:
Tasks are organized into groups that are processed one after the other. One group must finish before the next group starts, maintaining a strict sequence in execution.
 Figure 3.0: Sequential batching strategy
Figure 3.0: Sequential batching strategy
Example: In a manufacturing line, a machine produces 10 units of product A before switching to produce product B. The machine finishes all units of product A before it begins product B, following a sequential order.
Transfer Batching:
Tasks from different batches are passed to a final processing stage. After forming initial batches, tasks are transferred for further execution, combining elements while maintaining the batch size limit.
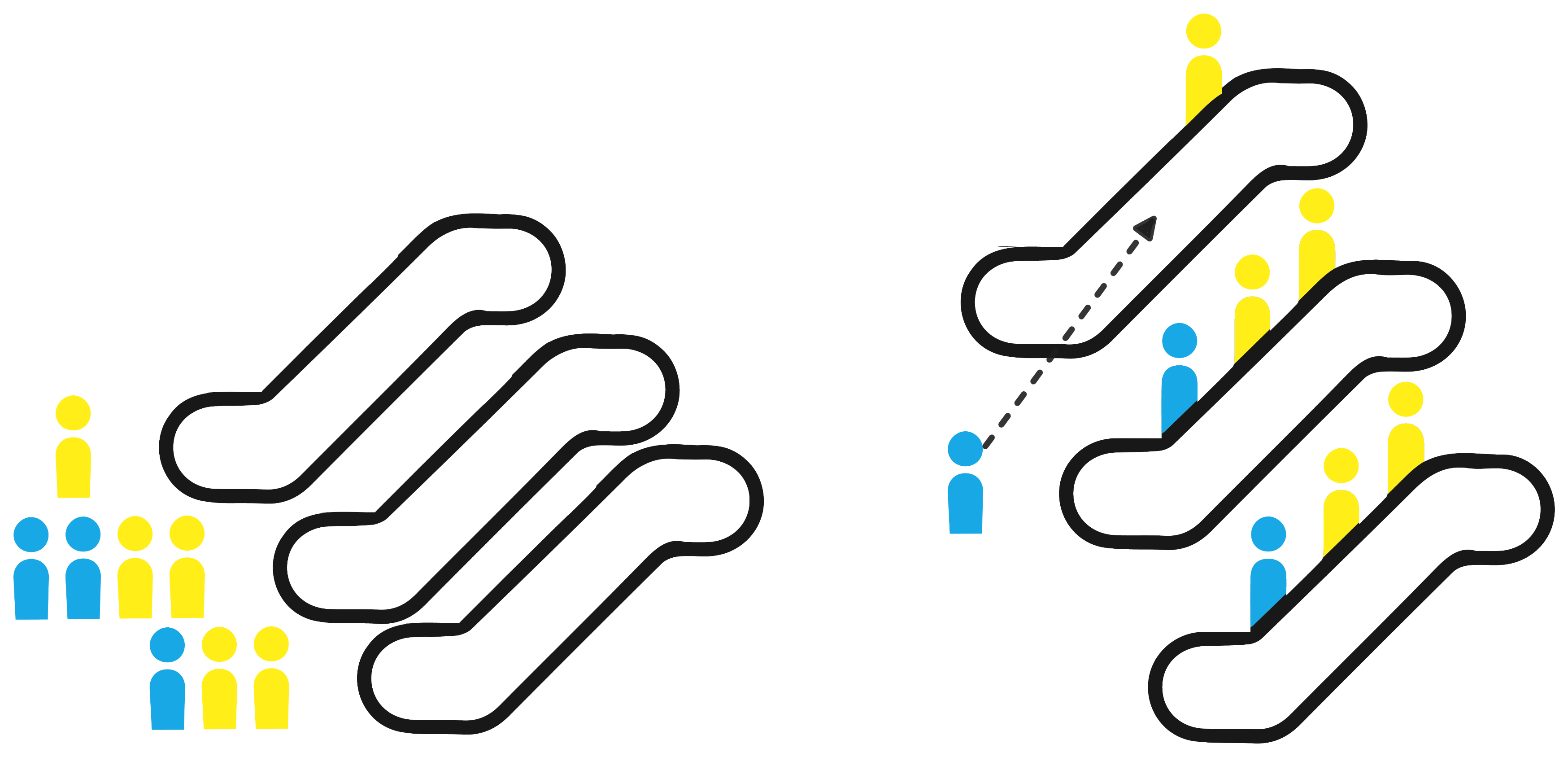 Figure 4.0: Transfer batching strategy
Figure 4.0: Transfer batching strategy
Example:
Imagine several groups of people taking different escalators to reach a single floor. Once they all reach the top, they gather together and move as a group to their final destination.
Batching can be fixed or dynamique , Fixed Batch Size refers to using a predefined, constant number of samples for each batch during the inference process, in contrast with more flexible batching strategies.
Dynamic Batch Sizing is a technique for microbatch inference where the batch size is continuously adjusted during the inference process based on factors such as input data characteristics and model performance.
Implementation
In Bentoml & Seldon Core, there’s a concept called adaptive batching that’s similar to the other batching strategies
https://mlserver.readthedocs.io/en/latest/user-guide/adaptive-batching.html#user-guide-adaptive-batching–page-root https://docs.bentoml.com/en/latest/guides/adaptive-batching.html
This implementation demonstrates how to build a BentoML runner that cleanly encapsulates the core functionality of an API for inference.
Here’s a step-by-step guide on how to go from defining a machine learning model to deploying a BentoML service that leverages functional programming and adaptive batching:
1. Define and Save the Model
You begin by training and saving your model using BentoML. For example, using a TensorFlow/Keras model:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import tensorflow as tf
import bentoml
# Define and train your model (this is just an example)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# Train your model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Assume you have some training data
# model.fit(X_train, y_train, epochs=5)
# Save your model with BentoML
bentoml.keras.save_model("my_model", model)
2. Create a BentoML Runner for the Model
The BentoML runner is responsible for running the model, especially when batching is required. Create a runner for your model with batch support:
1
2
3
4
5
6
7
8
9
10
import bentoml
# Load the saved model and create a runner
model_runner = bentoml.keras.get("my_model:latest").to_runner()
# Configure the runner with adaptive batching
model_runner.configure(
max_batch_size=32, # Set max batch size
max_latency_ms=200 # Set max wait time in milliseconds for batching
)
3. Define the BentoML Service
Next, create a BentoML Service that exposes the model as an API. Use functional programming principles to keep the logic clean, and use BentoML’s batching functionality.
1
2
3
4
5
6
7
8
9
10
11
12
13
import bentoml
from bentoml.io import NumpyNdarray
# Create the BentoML service
service = bentoml.Service("my_model_service", runners=[model_runner])
# Define the inference API using a function
@service.api(input=NumpyNdarray(), output=NumpyNdarray(), batch=True)
async def predict(input_data):
"""
This function handles model inference with adaptive batching.
"""
return await model_runner.run_batch(input_data)
4. Run the BentoML Service
Once you’ve defined the service, you can run it locally for testing or deploy it using BentoML’s deployment options (Docker, Kubernetes, etc.).
To run the BentoML service locally, use the following command:
1
bentoml serve my_model_service:latest --reload
This starts a REST API server where you can send batched requests to your model.
5. Deploy the Service
BentoML supports various deployment options, such as Docker, AWS Lambda, or Kubernetes. You can package your service as a Docker container for scalable deployment.
To containerize the service, run:
1
bentoml containerize my_model_service:latest
Then, you can deploy this container to your preferred platform (Kubernetes, AWS, etc.).